
Data quality is often overlooked in AI projects, yet it's the foundation upon which all successful implementations are built. We've seen countless projects fail not because of poor algorithms or inadequate computing power, but because of fundamental data quality issues that could have been prevented with proper planning and validation.
The Real Cost of Poor Data Quality
Consider this: a Fortune 500 company spent $2.3 million developing a customer recommendation engine, only to discover that their customer data contained 40% duplicates and inconsistent formatting across different systems. The AI model learned these patterns and began recommending products to the same customers multiple times under different names.
"Garbage in, garbage out" isn't just a programming principle - it's the number one reason AI projects fail in production.
Dr. Maria Rodriguez, Chief Data Scientist at DataFlow Industries
The Numbers Don't Lie
Recent industry research reveals some sobering statistics:
- 67% of AI projects fail due to data quality issues
- Companies lose an average of $15 million annually from poor data quality
- 89% of data scientists spend more time cleaning data than building models
- Only 23% of organizations have comprehensive data quality frameworks
Common Data Quality Issues That Kill AI Projects
1. Inconsistent Data Formats
Impact: Machine learning algorithms struggle to parse temporal patterns when dates are stored in multiple formats, leading to poor model performance and incorrect predictions.
2. Missing and Null Values
Missing data isn't just an inconvenience - it's a model killer. Consider these scenarios:
| Data Type | Missing % | Impact Level |
|---|---|---|
| Customer ID | 5% | Critical |
| Purchase Amount | 15% | High |
| Product Category | 25% | Medium |
| User Preferences | 45% | Low |
3. Duplicate Records
Duplicate data creates several problems:
- Inflated performance metrics: Models appear more accurate than they actually are
- Biased learning: Certain patterns get overrepresented
- Resource waste: Processing the same information multiple times
- Compliance issues: GDPR and other regulations require data minimization
Building a Data Quality Framework
Phase 1: Assessment and Discovery
Start with a comprehensive audit of your existing data:
- Data profiling: Understand the structure, content, and relationships
- Quality scoring: Develop metrics for completeness, accuracy, and consistency
- Impact analysis: Identify which quality issues affect business outcomes most
Phase 2: Cleaning and Standardization
Key standardization tasks:
- Normalize text casing and formatting
- Standardize date/time formats
- Clean and validate contact information
- Remove or flag obvious outliers
Phase 3: Validation and Monitoring
Implement ongoing quality checks:
Real-time Validation Rules
Advanced Data Quality Techniques
Statistical Outlier Detection
Use statistical methods to identify anomalous data points:
- Z-score analysis: Flag values more than 3 standard deviations from the mean
- Interquartile range (IQR): Identify values outside Q1 - 1.5×IQR or Q3 + 1.5×IQR
- Isolation forests: Machine learning approach for multivariate outlier detection
Data Lineage Tracking
Maintain a clear audit trail of data transformations:
- Source identification: Where did each data point originate?
- Transformation history: What processing steps were applied?
- Quality checkpoints: When and how was the data validated?
- Impact analysis: How do upstream changes affect downstream systems?
Tools and Technologies for Data Quality
Open Source Solutions
- Great Expectations: Python library for data validation and documentation
- Apache Griffin: Data quality solution for big data
- Pandas Profiling: Automatic EDA and quality reporting for Python
- Deequ: Amazon's data quality library for Apache Spark
Enterprise Platforms
- Informatica Data Quality: Comprehensive data cleansing and monitoring
- Talend Data Quality: Integrated data quality and preparation
- IBM InfoSphere QualityStage: Enterprise-grade data quality platform
- Microsoft Data Quality Services: SQL Server-integrated quality management
Measuring Success: Key Metrics
Track these essential data quality metrics:
Completeness Metrics
- Fill rate: Percentage of non-null values per field
- Schema compliance: Adherence to defined data structures
- Temporal completeness: Data availability across time periods
Accuracy Metrics
- Validation rate: Percentage of records passing business rules
- Reference match rate: Alignment with authoritative data sources
- Cross-field consistency: Logical relationships between data elements
Timeliness Metrics
- Freshness: How recently was the data updated?
- Latency: Time between data generation and availability
- Currency: Is the data still relevant for its intended use?
Case Study: Transforming a Failing AI Project
The Challenge
A major retailer's personalization engine was producing irrelevant product recommendations, leading to:
- 23% decrease in click-through rates
- $1.2 million in lost quarterly revenue
- Customer satisfaction scores dropping from 4.2 to 3.1
The Investigation
Our data quality audit revealed:
| Issue | Prevalence | Business Impact |
|---|---|---|
| Duplicate customer profiles | 31% | High |
| Inconsistent product categories | 18% | Medium |
| Outdated preference data | 52% | Critical |
| Missing transaction timestamps | 8% | Low |
The Solution
Week 1-2: Data Consolidation
- Implemented fuzzy matching to identify duplicate customers
- Created master data management (MDM) system
- Established golden record creation process
Week 3-4: Schema Standardization
- Normalized product taxonomy across all channels
- Standardized customer attribute formats
- Implemented real-time validation pipelines
Week 5-6: Historical Data Cleanup
- Developed ML models to predict missing values
- Implemented time-decay algorithms for preference weighting
- Created data quality dashboards for ongoing monitoring
The Results
After 6 weeks of intensive data quality improvements:
- Recommendation accuracy improved by 34%
- Customer engagement increased by 28%
- Revenue attribution from recommendations grew by $890K quarterly
- Data processing time reduced by 45%
Best Practices for Sustainable Data Quality
1. Implement Quality by Design
Build quality checks into your data pipelines from the beginning:
2. Establish Data Ownership
Assign clear responsibility for data quality:
- Data stewards: Business users who understand data context
- Data custodians: Technical teams responsible for implementation
- Data governance council: Cross-functional oversight body
3. Create Feedback Loops
Enable continuous improvement through:
- User feedback mechanisms: Allow data consumers to report issues
- Automated quality monitoring: Real-time alerts for quality degradation
- Regular quality reviews: Periodic assessment of quality metrics and processes
4. Invest in Data Literacy
Train your team on:
- Understanding data quality dimensions
- Recognizing common quality issues
- Using quality tools and techniques
- Implementing quality best practices
The Future of Data Quality
Emerging Trends
AI-Powered Quality Management Machine learning is revolutionizing data quality through:
- Automated anomaly detection
- Intelligent data profiling
- Predictive quality monitoring
- Self-healing data pipelines
Real-Time Quality Processing Stream processing enables:
- Immediate quality validation
- Real-time anomaly alerts
- Dynamic quality scoring
- Continuous data improvement
Collaborative Quality Management Modern platforms provide:
- Crowdsourced quality feedback
- Collaborative data documentation
- Shared quality standards
- Community-driven improvements
Conclusion: Quality as a Competitive Advantage
In today's data-driven economy, data quality isn't just a technical requirement - it's a competitive advantage. Organizations that prioritize data quality see:
- Higher AI project success rates (85% vs. 33% industry average)
- Faster time-to-market for data products
- Better regulatory compliance and reduced risk
- Improved customer satisfaction through better insights
The question isn't whether you can afford to invest in data quality - it's whether you can afford not to.
More Insights
Continue exploring our latest thinking on AI, automation, and technology trends.
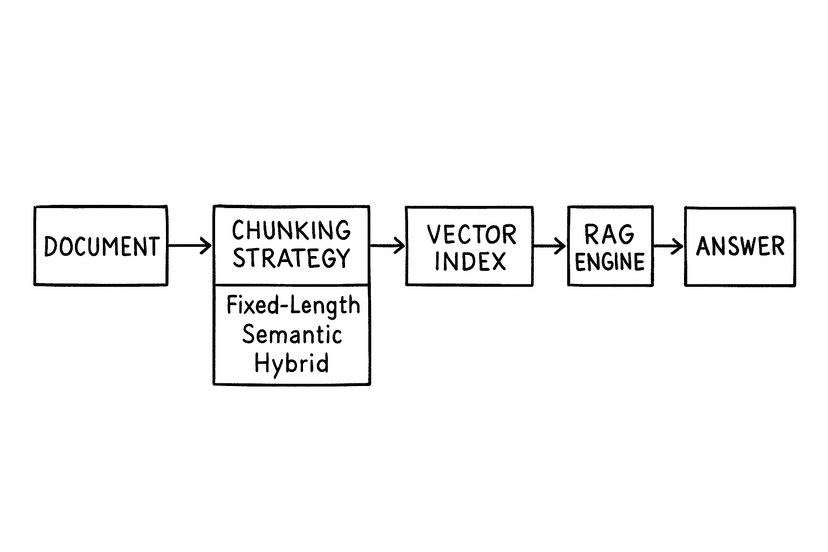
Overview of Chunking Strategies
Chunking is how you slice documents so RAG can retrieve the right facts within a model’s context window.

Why Data Quality Determines Success
Poor data quality is the silent killer of AI projects. Learn how to identify, fix, and prevent data issues.
Ready to implement these insights?
Let's discuss how these concepts can be applied to your specific business challenges and opportunities.