Building a classifier for very large text documents
95% accurate. Weeks to 30 seconds. 1,000+ docs organized. 500 hours saved.
Project Overview
A client asked us to classify 1,000+ internal documents with codes that do not exist in public taxonomies. The files were for publication, so they had to be easy to find by the target audience.
- 1,000+ documents
- 60–300 pages each (average 150–200)
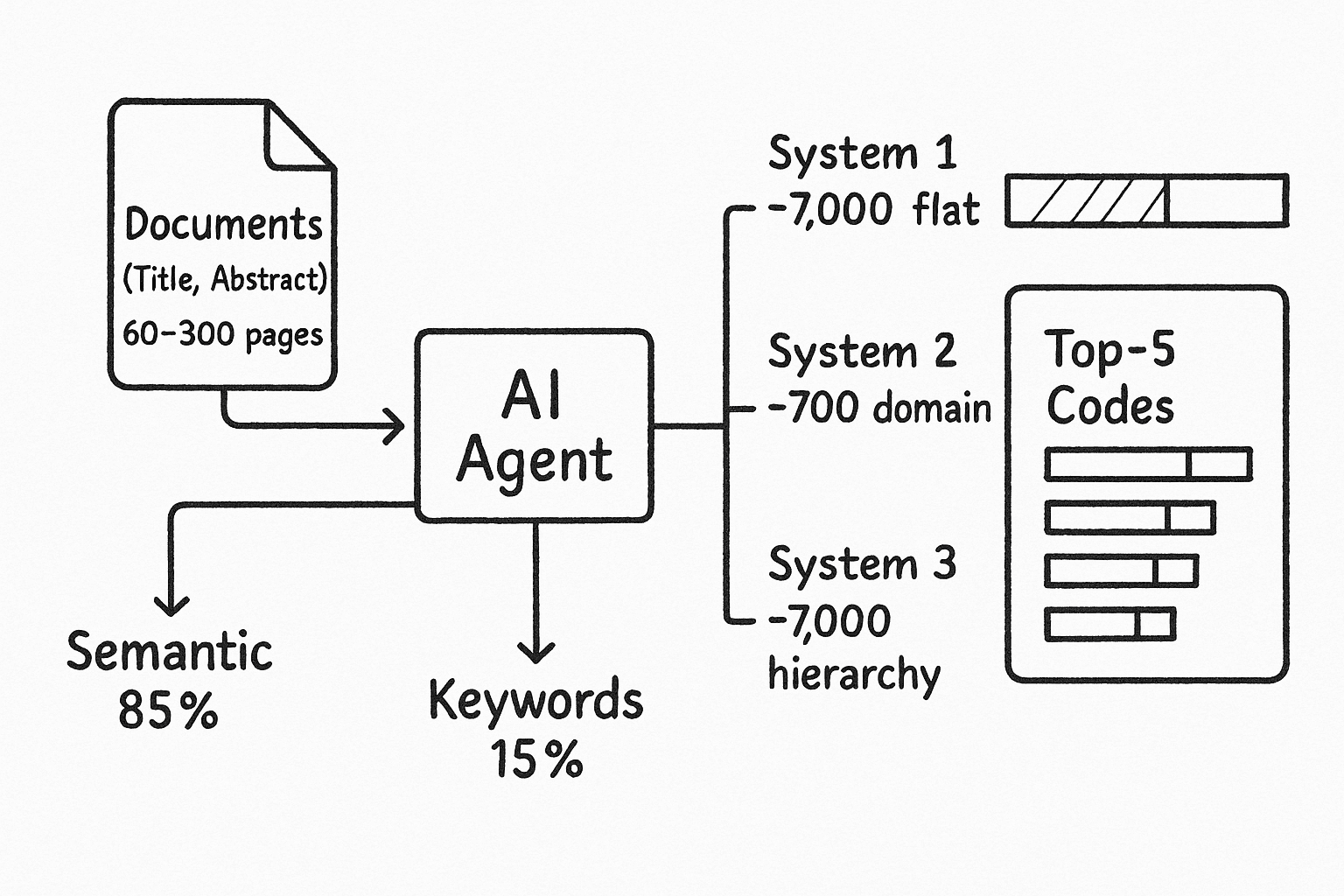
- Three code systems:
- System 1: ~7,000 codes (flat)
- System 2: ~700 codes (specialized)
- System 3: ~7,000 codes (hierarchy: general → specific → highly specific)
Classification systems (3 categories):
- First system: ~7,000 codes (flat structure)
- Second system: ~700 codes (specialized domain)
- Third system: ~7,000 codes with hierarchical structure (general → specific → highly specific)
Each code has an article number and a short description (~120 characters). Request was to built an AI agent that assigns the right codes to each document.
Key Challenges
The codes are internal and not in public databases. Standard models do not know them, so we needed a custom zero-shot approach.
Codes are short (~120 characters), while documents are long (60–300 pages). This size gap makes comparison hard.
Only the client’s experts knew the rules; our team had no prior examples.
Each document needs codes from three systems at once, so we had to process them in parallel.
Our Solution
We built a production-ready RAG classifier for very long documents (60–300 pages). It maps each file to codes in three systems in about 30 seconds. Every result includes page-level evidence and a confidence score.
We turned ~14,000 internal codes into simple “concept cards”: code ID, short description, common names, and full parent–child path. We added domain synonyms and near-miss negatives. With subject-matter experts we built a small, high-quality set of true matches and counter-examples to guide thresholds and evaluation.
We parse titles, abstracts, headings, sections, and tables, then chunk the text with a small overlap so meaning is not lost. We keep helpful signals like section paths, page numbers, acronyms, and definition patterns. Titles and abstracts get extra weight.
For each system we keep a dense semantic index and a sparse lexical index, query both, and merge. A cross-encoder reranker boosts precision. Hierarchy proximity nudges the model from a likely parent to the specific child. The LLM reasons over a short candidate list and outputs structured JSON with code, rationale, page-anchored evidence, and confidence (exact spans required). We use a conservative sampling setting for stable results, and guardrails block out-of-ontology codes, missing evidence, or conflicting siblings.
We started with n8n and moved to LangChain for finer control. Specialized agents run each step: ingestion removes PII; per-system retrievers run hybrid search; reranking tightens candidates; the classifier “rerank-then-reasons” and extracts evidence; a hierarchy pass checks path consistency; and a calibrator turns raw scores into reliable confidences via isotonic or temperature scaling on the SME-labeled set. A final validator packages results, deduplicates near-equivalents, and produces a Top-5 per system with short rationales and clickable evidence links.
The pipeline runs in parallel. Chunking and batched retrieval keep latency low. Indexes hot-reload when codes or descriptions change. Dashboards track precision@1/@5, per-system accuracy, hierarchy errors, and performance by document length and section density. Low-confidence cases go to human experts; their decisions update the gold set and improve the system.
User just upload a document and get the most relevant codes for each system with clear reasoning and page citations. In production we reached ~95% accuracy, processed 1,000+ documents, and cut days of work to ~30 seconds per file, saving 500+ hours while keeping experts in the loop.
What we've learned
building this
Key insights and lessons from this project that shaped our approach to future AI implementations.
Hybrid approach outperforms pure semantic search
Dense + sparse combination delivers better results than each method separately. Pure semantic search is good for conceptual understanding but misses exact terms. Pure BM25 is effective for keyword matching but doesn't understand synonyms and context. The hybrid approach (85/15 ratio) balances both methods perfectly, while solo implementation doesn't deliver results at all.
Weighted vector averaging is critically important
Simple averaging of all chunks causes the document body to "drown out" important metadata (title, annotation). We decided to implement weighted averaging with weight coefficients. Result: ~15% improvement in TOP-1 accuracy compared to uniform averaging.
Context window limitations require selection strategy
You can't "cram" the entire document into embedding. A strategy is needed: Prioritization, Limit, Chunking. More tokens = more coverage, but higher cost and slower processing.
Zero-shot classification is possible even for domain-specific codes
Even without model fine-tuning, the right retrieval system architecture delivers high accuracy. Quality embeddings, proper knowledge indexing, hybrid approach. What was NOT needed: Model fine-tuning on custom dataset; Creating labeled training data; Training classifiers from scratch.
Key Results
Processing time
Accuracy
Hours saved
Implementation Process
Introduction
First try
Regroup
Architecture & Development
Testing & Optimization
Maintenance & Dataset Enrichment

Ready to transform your business?
Let's discuss how AI can solve your specific challenges. Our team is ready to build custom solutions that deliver measurable results.